I am rather full of self-loathing after spending so much time using generative AI tools today. But this was actually really useful.
Our team uses a List in our MS Teams site to track projects - their status, contributors, due dates, etc. It started as a small list that was pretty manageable, but has grown into a list with 99 items. Data has been entered organically, so it’s not like it’s a fully normalized database with rigid taxonomies etc. So, making sense of it has become more of a challenge.
So.
I tried using ChatGPT-4o, to see if it would be able to help me visualize the data. I’d used previous versions of ChatGPT and MS Copilot, and didn’t have a lot of luck.
🤖 - AI-Generated Content via ChatGPT 4o
Prompt:
I have a List of projects in MS Teams. It has the following fields:
- Project
- Description
- Progress
- Start Date
- Due Date
- Priority
- Created By
- Contributors
- Notes
- Created Date
I need to make a timeline visualization of the data so that I can see the flow of projects - are there times with lots of concurrent projects? are there times with few concurrent projects? Are there team members who are contributing to many simultaneous projects? Are there team members who don’t have many simultaneous projects?
Can you please show me how to build such a visualization? I can also export the data as a .csv file to process externally if that helps.
Response:
To create a timeline visualization of your project data, we can follow these steps:
- Export the Data: Export your project data from MS Teams to a CSV file.
- Process the Data: Use Python to process the data and create a timeline visualization.
- Visualize the Data: Use a library like
matplotliborplotlyto create the timeline visualization.
Please export your data to a CSV file and share it with me. Once I have the file, I can help you process and visualize the data.
OK. So I exported the List as a .csv and uploaded it.
🤖 - AI-Generated Content via ChatGPT 4o
To create a timeline visualization based on the project data, we’ll focus on the Start Date and Due Date fields to identify periods with overlapping projects. We will also analyze the Contributor(s) field to determine which team members are involved in multiple projects simultaneously.
Here are the steps:
- Process Dates: Convert the
Start DateandDue Datefields to datetime format. - Calculate Overlaps: Determine the periods of overlap among projects.
- Visualize Timeline: Create a Gantt chart to visualize the project timelines and overlaps.
- Analyze Contributors: Identify contributors and visualize their involvement across projects.
Let’s proceed step by step.
Step 1: Process Dates
First, we need to convert the Start Date and Due Date fields to datetime format and handle any missing values.
Step 2: Calculate Overlaps
Next, we’ll calculate the periods of overlap among projects.
Step 3: Visualize Timeline
Finally, we’ll create a Gantt chart to visualize the project timelines.
Let’s implement this in Python.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# Load the CSV file
file_path = '/mnt/data/Projects.csv'
projects_df = pd.read_csv(file_path)
# Convert 'Start Date' and 'Due Date' to datetime format
projects_df['Start date'] = pd.to_datetime(projects_df['Start date'], errors='coerce')
projects_df['Due date'] = pd.to_datetime(projects_df['Due date'], errors='coerce')
# Drop rows where 'Start date' or 'Due date' is NaT
projects_df.dropna(subset=['Start date', 'Due date'], inplace=True)
# Sort the dataframe by 'Start date'
projects_df.sort_values(by='Start date', inplace=True)
# Reset index after sorting
projects_df.reset_index(drop=True, inplace=True)
# Display the dataframe to verify changes
projects_df.head()
This code will process the dates and prepare the dataframe for visualization. Once the data is processed, we’ll move on to creating the Gantt chart. Let me implement this part for you.
The data is now processed correctly. Next, we’ll create a Gantt chart to visualize the project timelines and overlaps. Additionally, we’ll analyze the contributors to see who is working on multiple projects simultaneously.
Creating the Gantt Chart
We’ll use matplotlib to create the Gantt chart.
Step 3: Visualize Timeline
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# Set up the figure and axis
fig, ax = plt.subplots(figsize=(14, 8))
# Plot each project as a horizontal bar
for idx, row in projects_df.iterrows():
ax.barh(row['Project'], (row['Due date'] - row['Start date']).days, left=row['Start date'], color='skyblue', edgecolor='black')
# Set the date format on the x-axis
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.MonthLocator())
# Rotate date labels for better readability
plt.xticks(rotation=45)
# Set labels and title
ax.set_xlabel('Date')
ax.set_ylabel('Projects')
ax.set_title('Project Timeline Gantt Chart')
# Show grid
ax.grid(True, which='both', linestyle='--', linewidth=0.5)
# Show the plot
plt.tight_layout()
plt.show()
This code will create a Gantt chart displaying the timelines for each project.
Step 4: Analyze Contributors
To visualize the contributions of team members across multiple projects, we can create a similar Gantt chart but grouped by contributors.
Contributor Analysis Visualization
# Split contributors and explode the dataframe
projects_df['Contributor(s)'] = projects_df['Contributor(s)'].fillna('')
projects_exploded_df = projects_df.assign(Contributor=projects_df['Contributor(s)'].str.split(';')).explode('Contributor')
# Clean up any extra spaces around contributor names
projects_exploded_df['Contributor'] = projects_exploded_df['Contributor'].str.strip()
# Set up the figure and axis
fig, ax = plt.subplots(figsize=(14, 8))
# Plot each project for each contributor
for idx, row in projects_exploded_df.iterrows():
ax.barh(row['Contributor'], (row['Due date'] - row['Start date']).days, left=row['Start date'], color='lightgreen', edgecolor='black')
# Set the date format on the x-axis
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.MonthLocator())
# Rotate date labels for better readability
plt.xticks(rotation=45)
# Set labels and title
ax.set_xlabel('Date')
ax.set_ylabel('Contributors')
ax.set_title('Contributor Project Involvement Timeline')
# Show grid
ax.grid(True, which='both', linestyle='--', linewidth=0.5)
# Show the plot
plt.tight_layout()
plt.show()
Let’s implement this in Python and generate the visualizations.
It looks like there was an issue with handling empty or missing values in the contributor field. I’ll add some checks to ensure we’re only processing valid data points.
Let’s update the code and reattempt the visualization for contributors.
Updated Code for Contributor Analysis Visualization
# Ensure there are no missing or empty strings in the 'Contributor' column
projects_exploded_df = projects_exploded_df[projects_exploded_df['Contributor'] != '']
# Set up the figure and axis for contributors
fig, ax = plt.subplots(figsize=(14, 8))
# Plot each project for each contributor
for idx, row in projects_exploded_df.iterrows():
ax.barh(row['Contributor'], (row['Due date'] - row['Start date']).days, left=row['Start date'], color='lightgreen', edgecolor='black')
# Set the date format on the x-axis
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.MonthLocator())
# Rotate date labels for better readability
plt.xticks(rotation=45)
# Set labels and title
ax.set_xlabel('Date')
ax.set_ylabel('Contributors')
ax.set_title('Contributor Project Involvement Timeline')
# Show grid
ax.grid(True, which='both', linestyle='--', linewidth=0.5)
# Show the plot
plt.tight_layout()
plt.show()
I’ll run the updated code now.
Here are the visualizations:
Project Timeline Gantt Chart: This chart shows the timeline of each project, indicating the periods when projects are running concurrently.
Contributor Project Involvement Timeline: This chart shows the involvement of each contributor across different projects, highlighting who is working on multiple projects simultaneously.
These visualizations should help you analyze the flow of projects and the workload distribution among team members. If you need any further adjustments or additional analysis, please let me know!
There was some back-and-forth, and it struggled with basic stuff like “including all rows from the csv”, but it did a surprisingly good job! I wasn’t as interested in the “Contributor” visualization, and wanted to focus on the timeline chart.
After I convinced it to include all rows, and to use the date in the “Created” field for “Start date” for any items that didn’t have an explicit start date, it came up with this - an interactive timeline view that lets you select specific time ranges by dragging on the chart.
Here’s the final output, with the working Python code to generate the interactive chart1:
🤖 - AI-Generated Content via ChatGPT 4o
The interactive timeline chart has been updated to use ‘2023-07-01’ as the default date for projects without a “Due date” and has been saved as an HTML file. You can download and view it locally using the following link:
Download Updated Project Timeline Chart
Here is the updated full Python script:
import pandas as pd
import plotly.express as px
# Set the new default date
default_date = pd.Timestamp('2023-07-01')
# Reload the CSV file to ensure all projects are included
projects_full_df = pd.read_csv('/mnt/data/Projects.csv')
# Convert 'Start date', 'Due date', and 'Created' to datetime format
projects_full_df['Start date'] = pd.to_datetime(projects_full_df['Start date'], errors='coerce')
projects_full_df['Due date'] = pd.to_datetime(projects_full_df['Due date'], errors='coerce')
projects_full_df['Created'] = pd.to_datetime(projects_full_df['Created'], errors='coerce')
# Use 'Created' date for missing 'Start date'
projects_full_df['Start date'] = projects_full_df['Start date'].fillna(projects_full_df['Created'])
# Fill missing 'Due date' with the new default date
projects_full_df['Due date'] = projects_full_df['Due date'].fillna(default_date)
# Replace nan values in 'Priority' with 'None'
projects_full_df['Priority'] = projects_full_df['Priority'].fillna('None')
# Create a Gantt chart using Plotly
fig = px.timeline(
projects_full_df,
x_start="Start date",
x_end="Due date",
y="Project",
color="Priority",
title="Project Timeline",
labels={"Priority": "Priority Level"},
template="plotly_white"
)
# Update layout for better readability
fig.update_layout(
xaxis_title="Date",
yaxis_title="Projects",
yaxis=dict(
titlefont=dict(size=10),
),
xaxis=dict(
titlefont=dict(size=10),
tickformat="%Y-%m-%d",
),
title=dict(x=0.5),
hoverlabel=dict(
bgcolor="white",
font_size=12,
font_family="Rockwell"
)
)
fig.update_yaxes(categoryorder="total ascending")
# Save the interactive plot as an HTML file
html_file_path = '/mnt/data/project_timeline_full_corrected_with_created_2023-07-01.html'
fig.write_html(html_file_path)
print(f"Chart saved to {html_file_path}")
This script ensures that projects without a “Due date” use ‘2023-07-01’ as the default date and includes all necessary data for visualization.
I mean. That’s kind of impressive. I would definitely NOT have been able to write that code without spending like a week learning Python. But ChatGPT-4o eventually produced code that generates a workable visualization of some semi-structured data, in maybe an hour’s worth of fiddly back-and-forth. The visualization appears to only include 49 projects - where did the other 50 go? Maybe it’s a data quality issue - or did it only include projects that also had “Due date” values? (which, if so, that’s easy to fix…)
Actually… Why not just ask ChatGPT-4o to fix that?
🤖 - AI-Generated Content via ChatGPT 4o
Prompt:
Closer. For projects that are missing “Due date” - if they have “Start date”, set “Due date” to be “Start date” plus 1 week. If they also don’t have “Start date” value, set “Due date” to be “Created” plus 1 week.
Response:
Let’s update the script to handle these specific conditions for setting the Due date:
- If a project is missing
Due datebut has aStart date, setDue dateto beStart dateplus 1 week. - If a project is missing both
Due dateandStart date, setDue dateto beCreatedplus 1 week.
Here’s the updated Python script:
import pandas as pd
import plotly.express as px
# Reload the CSV file to ensure all projects are included
projects_full_df = pd.read_csv('/mnt/data/Projects.csv')
# Convert 'Start date', 'Due date', and 'Created' to datetime format
projects_full_df['Start date'] = pd.to_datetime(projects_full_df['Start date'], errors='coerce')
projects_full_df['Due date'] = pd.to_datetime(projects_full_df['Due date'], errors='coerce')
projects_full_df['Created'] = pd.to_datetime(projects_full_df['Created'], errors='coerce')
# Use 'Created' date for missing 'Start date'
projects_full_df['Start date'] = projects_full_df['Start date'].fillna(projects_full_df['Created'])
# Set 'Due date' to 'Start date' + 1 week if 'Due date' is missing
projects_full_df['Due date'] = projects_full_df['Due date'].fillna(projects_full_df['Start date'] + pd.Timedelta(weeks=1))
# For projects missing both 'Start date' and 'Due date', set 'Due date' to 'Created' + 1 week
projects_full_df['Due date'] = projects_full_df.apply(
lambda row: row['Created'] + pd.Timedelta(weeks=1) if pd.isna(row['Due date']) else row['Due date'],
axis=1
)
# Replace nan values in 'Priority' with 'None'
projects_full_df['Priority'] = projects_full_df['Priority'].fillna('None')
# Create a Gantt chart using Plotly
fig = px.timeline(
projects_full_df,
x_start="Start date",
x_end="Due date",
y="Project",
color="Priority",
title="Project Timeline",
labels={"Priority": "Priority Level"},
template="plotly_white"
)
# Update layout for better readability
fig.update_layout(
xaxis_title="Date",
yaxis_title="Projects",
yaxis=dict(
titlefont=dict(size=10),
),
xaxis=dict(
titlefont=dict(size=10),
tickformat="%Y-%m-%d",
),
title=dict(x=0.5),
hoverlabel=dict(
bgcolor="white",
font_size=12,
font_family="Rockwell"
)
)
fig.update_yaxes(categoryorder="total ascending")
# Save the interactive plot as an HTML file
html_file_path = '/mnt/data/project_timeline_full_corrected_dates.html'
fig.write_html(html_file_path)
html_file_path
I’ll run this updated script to generate the visualization.
You can download and view it locally using the following link:
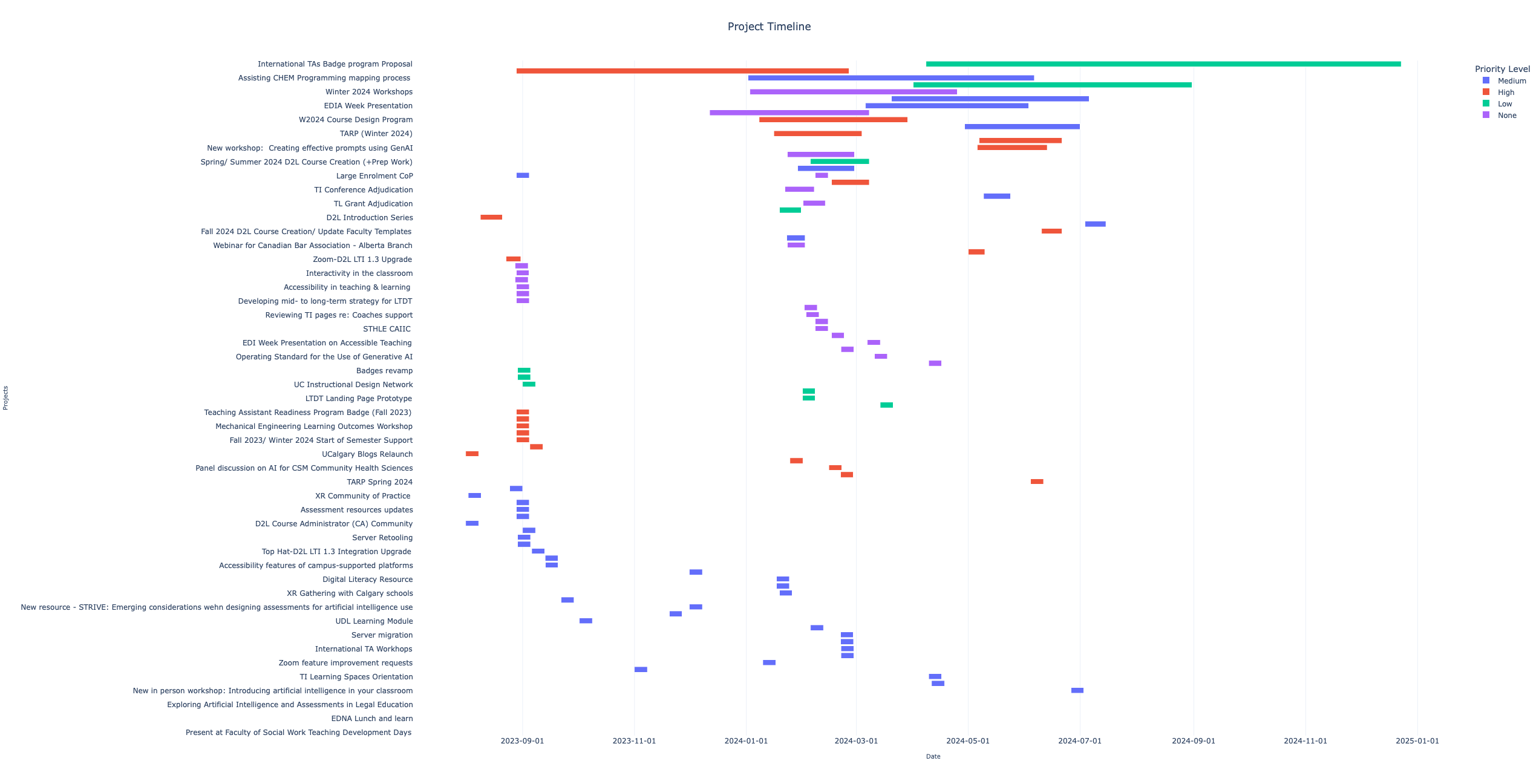 Snapshot of the interactive timeline visualization of the MS Teams List data
Snapshot of the interactive timeline visualization of the MS Teams List data
Bingo. That works perfectly. It sanitizes the data, sets defaults for missing data, and generates a usable visualization.
Let’s end this with some reality-checking.
🤖 - AI-Generated Content via ChatGPT 4o
Prompt:
What was the carbon footprint of all of our work to develop this visualization?
Response:
Estimating the carbon footprint of developing this visualization involves considering various factors, including the energy consumption of the hardware used (servers, networking equipment), the duration of computational tasks, and the energy sources of the data centers involved.
Factors to Consider:
Energy Consumption of Servers:
- The server running the computations.
- The network infrastructure.
Duration of Computational Tasks:
- The time taken for each step of the computation.
Energy Source of Data Centers:
- The mix of renewable and non-renewable energy sources.
Steps to Estimate:
Estimate the Energy Consumption:
- Determine the power usage effectiveness (PUE) of data centers, which is typically between 1.1 and 2.0.
- Estimate the energy consumption of the server (in kWh).
Estimate the Carbon Emission Factor:
- Determine the carbon emission factor for the electricity grid powering the data centers (in kg CO2e per kWh).
Simplified Estimation:
For a simplified estimation, let’s assume:
- A server with a power consumption of 500 watts (0.5 kW).
- A total computation time of 1 hour.
- A PUE of 1.5.
- A carbon emission factor of 0.5 kg CO2e per kWh.
Energy Consumption Calculation:
- Server energy consumption: 0.5 kW * 1 hour = 0.5 kWh.
- Total energy consumption with PUE: 0.5 kWh * 1.5 = 0.75 kWh.
Carbon Footprint Calculation:
- Carbon footprint: 0.75 kWh * 0.5 kg CO2e/kWh = 0.375 kg CO2e.
Final Estimate:
The carbon footprint for the computations involved in developing this visualization is approximately 0.375 kg CO2e.
This is a rough estimate and actual values can vary based on the specific infrastructure and energy sources used.
375 grams of carbon emitted to make a visualization of a .csv file. Oof.
I modified the URL linked from the ChatGPT-4o output, so that it pointed to a copy of the html file rather than to the ephemeral “sandbox” hosted by ChatGPT. ↩︎