⚙️ Work
Lots of meetings. We decided to simplify the classroom support model for people teaching in the classrooms on the main floor of the TI. When the building opened, we offered a LOT of support and consultation - technical, pedagogical, troubleshooting, etc. - in ways that weren’t offered to instructors teaching anywhere else on campus. Which was great for the instructors teaching downstairs, but meant they were treated differently. We’re going to focus more on consultation for all instructors, no matter where they teach on campus, and let IT’s Com/Media group do their thing to support the classroom tech. This should be much more sustainable for everyone involved.
We started the process of implementing content retention guidelines for our Brightspace servers. Since we launched in 2013, no course has been deleted. So, it’s kind of been accumulating over the last decade. For some reason, there was a pretty massive increase in file storage utilization, starting around the summer of 2020…
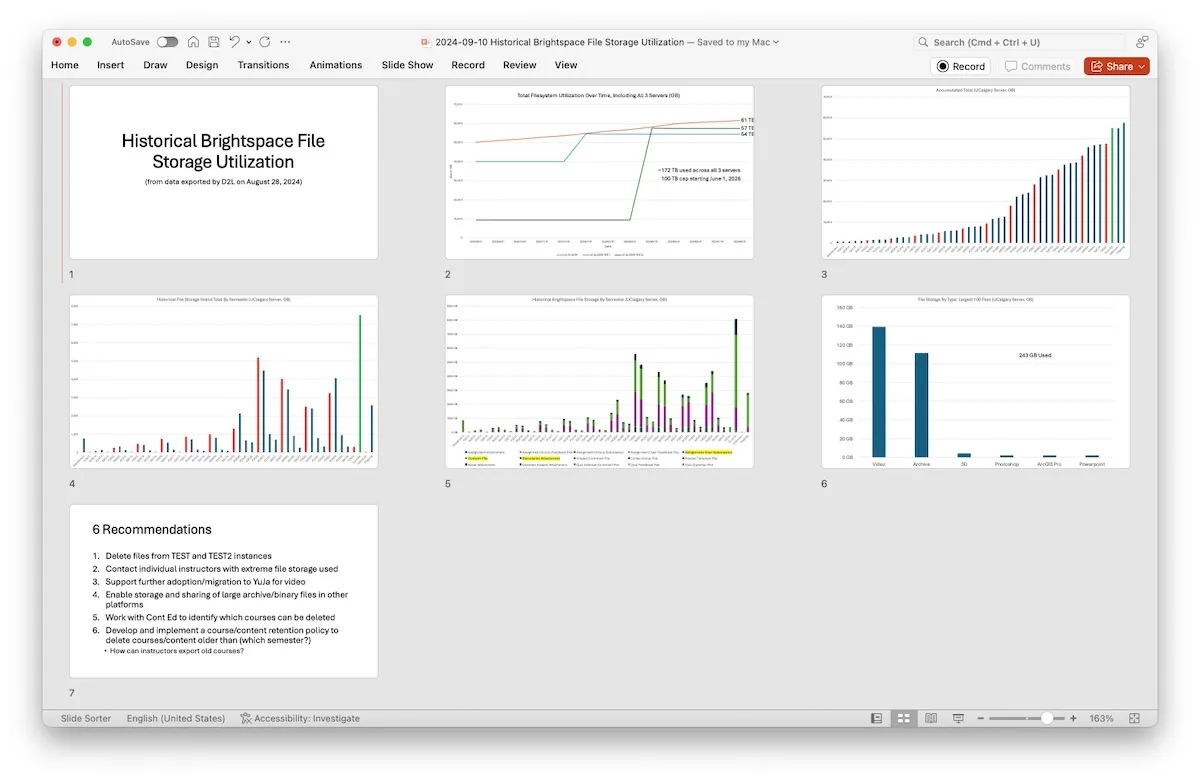 Historical file storage utilization in our main Brightspace environment.
Historical file storage utilization in our main Brightspace environment.
🔗 Links
Leadership
- Robert Winter: Building High(er)-Performing Teams: A Leader’s Guide to Collaboration and Success. The Welchian “lifeboat exercise” is a terrible idea and leans about as far from psychological safety as possible. The part about role clarity and communication are super important. I think lack of role clarity is at (or near) the root of many workplace challenges.
AI
Simon Sherwood @ The Register: We’re in the brute force phase of AI – once it ends, demand for GPUs will too (via Eric Likness). Now that we’ve made a graphics card company somehow worth $3T1… GenAI will eventually become more feasible on general-purpose kit.
Lee, K., Cooper, A.F., & Grimmelmann, J. (2024). Talkin’ ‘Bout AI Generation: Copyright and the Generative-AI Supply Chain (July 27, 2023). Forthcoming, Journal of the Copyright Society 2024, Available at SSRN: https://ssrn.com/abstract=4523551 or http://dx.doi.org/10.2139/ssrn.4523551 (via @DrPen & Alan Levine)
the Article introduces what we call the generative-AI supply chain: an interconnected set of stages that transform training data (millions of pictures of cats) into generations (a new and hopefully never-seen-before picture of a cat that may or may not ever have existed). Breaking down generative AI into these constituent stages reveals all of the places at which companies and users make choices that have legal consequences — for copyright and beyond.
Martin Weller @ The Ed Techie: Things I was wrong about pt 4 – AI
Martin’s post describes my reactions to GenAI as well. Initially, I was sure GenAI was just a fad based on a curious coincidence of “isn’t it interesting how it looks like it’s doing stuff”, which then, through the exuberant application of billions of dollars worth of hardware, somehow crossed a threshold where it actually works for a growing number of things.
I underestimated just what brute force computation can do. Forget finesse, and cognitive modelling, just throw terabytes of data at algorithms and they will find patterns. I am being harsh here of course, those training algorithms are very sophisticated, but the point is we didn’t need to replicate domains of knowledge, with sufficient datasets the number crunching could generate reasonable output without us telling it the rules.
And this connects to our previous history with Learning Object Repositories, where the general consensus was that we needed to develop Large Systems to manage Rigorous Metadata with Approved Specifications in order for anyone to be able to find anything. This is another case where Stephen Downes was right, when he proposed letting go of the focus on Metadata and just using Google and search engines rather than structured data. Heresy! That could never work! (except it did, brilliantly)
and
I think the impact of AI is wildly exaggerated and we’re probably heading for a bubble burst for all those companies investing heavily in it. But this doesn’t mean it isn’t having a significant impact. Even if we just look at the impact it is having in higher education, and the work required to rethink assessment, then it is pretty pervasive.
Rob Gibson @ EDUCAUSE Review: The Impact of AI in Advancing Accessibility for Learners with Disabilities
Ethan Mollick: Something New: On OpenAI’s “Strawberry” and Reasoning.
…the AI does so much thinking and heavy lifting, churning out complete results, that my role as a human partner feels diminished. It just does its thing and hands me an answer. Sure, I can sift through its pages of reasoning to spot mistakes, but I no longer feel as connected to the AI output, or that I am playing as large a role in shaping where the solution is going.
OpenAI released a preview of their new “ChatGPT-4o1” model, with “reasoning”. The “reasoning” appears to be “rerun the prompt a bunch of times, automating the stuff people have been doing manually to try to convince you to work around hallucinations”. It’s a quasi-brute-force approach, which seems to work, but also probably increases the resource demand by like 10X…
AI and Assessment
Sarah Eaton @ Learning, Teaching and Leadership: Ethical Reasons to Avoid Using AI Apps for Student Assessment.

Cameron, S., & Mesiti, C. (2024). What Kind of Mathematics Teacher is ChatGPT? Identifying the Pedagogical Practices Preferenced by Generative AI Tools When Preparing Lesson Plans. In J. Višňovská, E. Ross, & S. Getenet (Eds.), Surfing the waves of mathematics education. Proceedings of the 46th annual conference of the Mathematics Education Research Group of Australasia. (via Eliana Elkhouri & Soroush Sabbaghan).
People use GenAI to build lesson plans. This study starts to look at what kinds of pedagogical biases might creep in through that process. They had ChatGPT generate 4 lesson plans on mathematics, then evaluated the lesson plans.
In the case of lesson plans generated by ChatGPT, advice is provided for teachers on what to teach, but not how to teach it.
Nikolic, S., Daniel, S., Haque, R., et al. (2023). ChatGPT versus engineering education assessment: a multidisciplinary and multi-institutional benchmarking and analysis of this generative artificial intelligence tool to investigate assessment integrity. European Journal of Engineering Education, 48(4), 559–614. https://doi.org/10.1080/03043797.2023.2213169
The authors look into the “frenetic hubbub” about GenAI in higher education by trying various “prompt engineering” approaches to see if ChatGPT-generated responses could get passing grades on assessments. It passed some, failed some, and was too close to call for some. And they provide a list of recommendations for instructors in consideration of GenAI being a thing.
Course design
Jessica Gemella @ Vancouver Island University’s CIEL Blog: Assessment Design Decision Tool
An interesting new “assessment design decision tool” from Vancouver Island University. It’s basically a flowchart set up in a presentation, asking you questions about your course design. Like an old-timey “Choose Your Own Adventure” book, but for course design.
🧺 Other
AI explorations
This week’s ChatGPT-4o exploration involved building a D3.js visualization of my Obsidian notes. It looks cooler than the Obsidian graph view, but I don’t know if it adds anything.
And, building a simple gallery of projects in my webdev sandbox (which has been reduced to only 1 project, but could come in handy for some dabbling…)
I’ve been using Ollama to run LLMs locally on my laptop (which doesn’t have a ton of storage so I pick the smallest models). I just grabbed the latest llama3.1:8b model because it’s only 4.7 GB, and am trying it in the Ollamac interface. This works better than running it through Terminal. So far, the biggest limitation is the inability to access files. If I had MUCH more storage, I’d grab the full llama3.1:405b model - but that requires 229 GB just for the model and that won’t fit on my laptop’s SSD. Even the mid-range llama3.1:70B model requires 40 GB and that would be just enough to cause macOS to start offloading files to iCloud.
To test out llama3.1, I had it build a version of the webdev sandbox page. I think I like it better than the one built by ChatGPT-4o…
And I added the Local GPT plugin to Obsidian and configured it to use llama3.1. It has a surprisingly useful action for generating a list of action items in markdown task list format.
I tried the ideogram.ai image-generating LLM. It feels pretty much like ChatGPT’s version of DALL-E, but with less metal/plastic shine on the images? Still has LOTS of weird artifacts (people look like some nightmare combination of Playstation 1 polygons and weird projection mapping, and text looks like some hybrid of maybe Thai and Arabic?)
 Ideogram.ai-generated image of an active learning classroom at a university
Ideogram.ai-generated image of an active learning classroom at a university
Bloggity bloggenstein
I finally decided to try using Obsidian to edit content for my website. Hugo is all just Markdown, so it should Just Work™. And I get to use the other Obsidian tools rather than just using a plain Markdown editor like Typewriter (which is a really good Markdown editor). I just set up a new Vault by opening my Hugo content directory. That seems to have been it. Done.
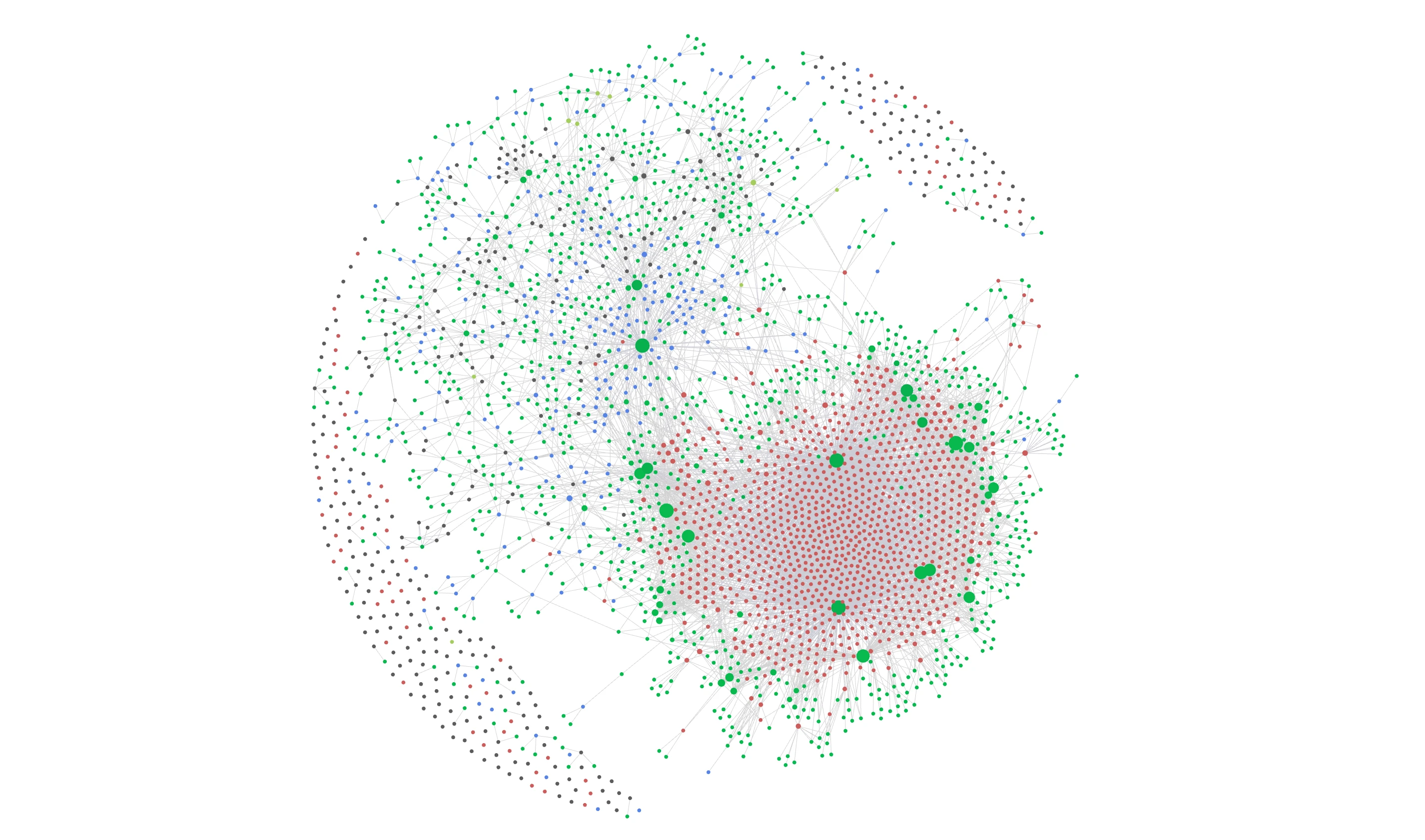 Graph view of my Hugo content as managed in Obsidian. Green dots are tags. Red dots are photos. That’s a lot of photos.
Graph view of my Hugo content as managed in Obsidian. Green dots are tags. Red dots are photos. That’s a lot of photos.
I re-enabled related content in Hugo, setting it up to only show for content types that make it to the front page (so, excluding all of the photos posts). It adds some time to building the site, but may be worth it for some serendipitous connections between posts. There will be a “See Also” section at the bottom of posts if Hugo found any related items.
AND the lunchtime skating season at the Olympic Oval started (well, I think it started last week but I missed that). I got out for a skate on Friday and wound up doing like 30 laps.
 Skating at the Olympic Oval
Skating at the Olympic Oval
🗓️ Focus for next week
- TI Strategic Planning Retreat
- Kickoff for the group that will be planning the implementation of our new Microcredentials Framework
so, more than the GDP of Canada, for one company, who make video cards that feed the crypto and AI bubbles… ↩︎